Product and NLP learnings from a Twitter bot

I’ve always been a big fan of Japanese literature, and Haruki Murakami comes out on the top of my mind as the most renowned contemporary of Japanese authors. I binged a lot on his collection of short essays in the first year back to Australia. His unique tone of writing and sense of humour on paper always make me feel like chatting with an old friend.
Murakami’s stories often have very vivid and clever descriptions of scenes, despite the mundanity of a daily routine. Not only is this captured in his novels, but also in his short stories and musings, such as those published in his book series Murakami Radio (coincidentally, the origin of the bot’s name).
For me, it’s that very strong sense of relatability: there is an essence of humanity in the words he chooses to describe his characters and the environments they are in.
What got me thinking was whether his style could be emulated. As a lot of his work is yet to be translated into English, especially his short essays with interesting anecdotes and first-person narrative, wouldn’t it be nice if we can have a bot that writes like your favourite author from whoever you are inspired from every single day? If Murakami himself could discover his own “style of Japanese” by expressing his feelings and thoughts with a limited set of words and grammatical structures, but effectively linking them in a skilful manner, can a machine learn from this pattern and compose simple yet beautiful phrases?
My friend Paul Tune and I thought it would be a fun project to try to build a Murakami bot using GPT-2 to try to capture his tone and style, all within Twitter’s character limits.
After presenting an overview of the product idea, in the rest of the article, I will detail the development process of Radio Murakami bot, from raw data collection, training using GPT-2, iterations and showcase some deep and relatable tweets by the bot.
Brief Bio of Haruki Murakami#
Most readers in the Western world are unfamiliar with Haruki Murakami.
Murakami was born in Kyoto in 1949, during the post-World War II economic boom. He has always loved music, especially jazz, so he opened a jazz bar in Tokyo with his wife. He ran the bar for 7 years.
As a child, Murakami grew up reading many Western works, from Franz Kafka, Charles Dickens to Kurt Vonnegut. One of his short stories, Samsa in Love is the sequel to the story of Gregor Samsa, the protagonist of Kafka’s The Metamorphosis.
Murakami’s writing career only began at 29, as he described in the article The Moment I Became a Novelist. In a baseball game between the Yakult Swallows and the Hiroshima Carp on one bright April afternoon in 1978, as he said -
“The satisfying crack when the bat met the ball resounded throughout Jingu Stadium. Scattered applause rose around me. In that instant, for no reason and on no grounds whatsoever, the thought suddenly struck me: I think I can write a novel.”
After the game, he went to Shinjuku to buy writing paper and a fountain pen. A little over six months later, his first novel Hear the Wind Sing was published in 1979.
Murakami only had a major breakthrough with his work, Norwegian Wood, a reference to the John Lennon song of the same name, in 1988. It was very popular with younger Japanese, and was eventually translated to English for a Western audience.
Preparing the Data#
Arguably, the most tedious and challenging part of any data science project is the preparation of data. This is no different in this case.
We almost scoured the entire web for any of the interviews available in English as we want the bot to talk and write with a direct touch from Murakami. The training data we have include:
- All of Murakami’s novels available, such as 1Q84 and the famous Norwegian Wood
- Short stories published in The New Yorker
- Murakami’s interviews (so that the bot can learn a first person perspective)
- Quotes in Twitter formats from Goodreads and Quote Catalog (this is to ensure that the model would learn to adapt Twitter style writing format rather than long-form texts)
There’s a caveat here. All of Murakami’s work is translated by various people from Japanese into English. As a result, the original meaning of sentences in Japanese and subtly in the choice of words may not be fully captured, which arguably is what Japanese language is famous for.
Fortunately, Murakami’s style is more Westernised compared to his peers, which means that capturing meaning in English might potentially not be as difficult as other Japanese authors.
The entire dataset collected for training is over 10 MB, and was further cleaned up manually by removing any non-English, non-Murakami related texts from interviews and quotes. There was also a lot of duplication in selected quotes by users on Goodreads, which we had to review and remove. We also have a separate training set of quotes, which I explain below.
Training the Model#
Here we use the GPT-2 model¹ developed by OpenAI, which is a causal (unidirectional) transformer pre-trained on a dataset of 8 million web pages and over 1.5 billion parameters from Common Crawl. GPT-2 is trained with an objective to predict the next words in a sentence, which is very similar to the autocomplete feature on our phones, but in a more sophisticated way.
The causal direction implies that the model can generate text in a sequential manner by predicting the next word given a word! Perfect for a bot.
Unlike the autocomplete feature, GPT-2 can handle sentence context which allows it to know the difference of a word when used in a sentence. Take the word fly in the following sentences for instance,
“The fly fell into the diner’s soup.”
and
“The invention of the airplane allowed people to fly.”
In this case, while the word fly is spelt the same, one denotes an insect (noun) while the other denotes an action (verb). By training on whole sentences and paragraphs, GPT-2 learns context, allowing it to differentiate the use of a word like fly in different contexts. This is an example of a homonym, a word which sounds the same but is unrelated in meaning. A word-based model such as Word2Vec³ cannot capture such context.
We used the medium size of GPT-2 with 345M parameters to train the Radio Murakami bot. Below is an illustration showing the distinctions among different size of GPT-2 models:
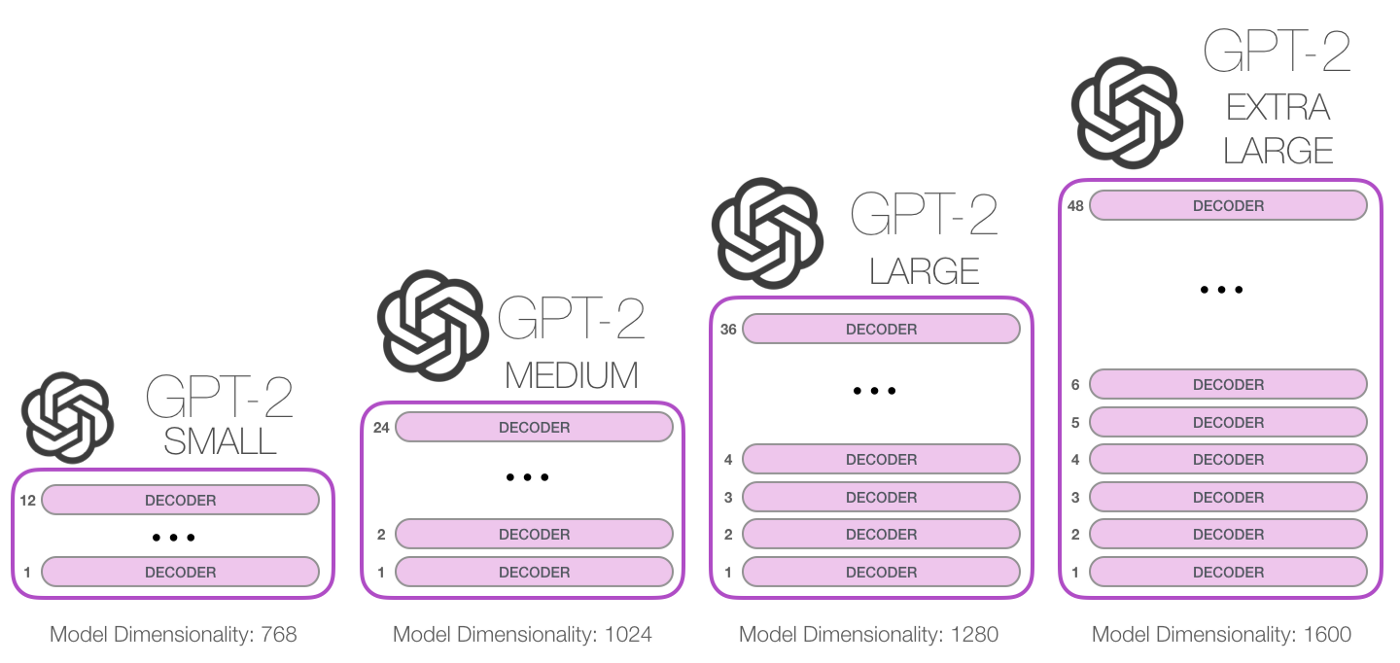
The heavy-lifting part of the model training has already been done in the pre-trained model itself, and GPT-2 already has a really good grasp of the English language. It takes text inputs as a sequence of tokens, and predicts the next output token in sequence, each having a probability as weights, in this way learning in a self-supervised manner. If you’re interested in finding out more about how the model works, Jay Alammar has a well-illustrated article visualising the underlying mechanism of GPT-2².
Initially, training involved writing a script that was clobbered with work from Max Woolf but with gradually improved functionality from the Hugging Face’s Transformer package, we used this script for training. The package also has functions that make it easy for sampling from the trained model.
Training the model was simple: all we had to do was to load the dataset into the model. With about 8 epochs or so, the model was trained and ready to be deployed!
Iterating#
One of the main challenges was getting the quotes down to Twitter-sized quotes. This turns out to be more difficult than expected. Once our initial model was trained on the novels, it learns how to generate prose from a novel and not a pithy tweet instead, which is what we want.
Here’s an example output of a novel-trained model:
“The sunlight shone down, the smell of flowers filling the air. I could see the gentle curve of the shore, the white sand. The sound of waves, rustling of leaves, the distant cry of cicadas.”
Whilst this makes for a great descriptive filler in a Murakami novel, it makes for a bad quote generator! We had to generate, review and curate a lot more samples to get what we wanted for the bot using this initial model.
In order to do better, we curated a set of quotes with tweet-like qualities as our dataset. By training the model on this dataset, the model is able to produce better quality output. Prior to this, the model used to generate excerpts that looks like a sampled prose from a Murakami novel. Now it produces a quote that someone would pick out from the novels. We also experimented by putting in the best generated by a model into the next training of the model, and this seemed to help, though we are aware of the self-reinforcing bias.
Even so, it is challenging to find quotes that are somewhat profound, and even more challenging to find one that Murakami would be proud of. We still currently act as humans-in-the-loop for curation, but are currently still experimenting with more advanced methods.
Results#
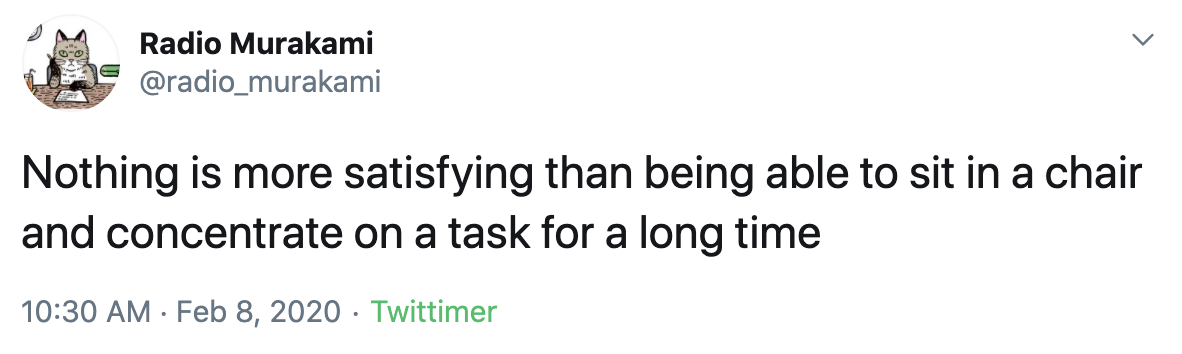
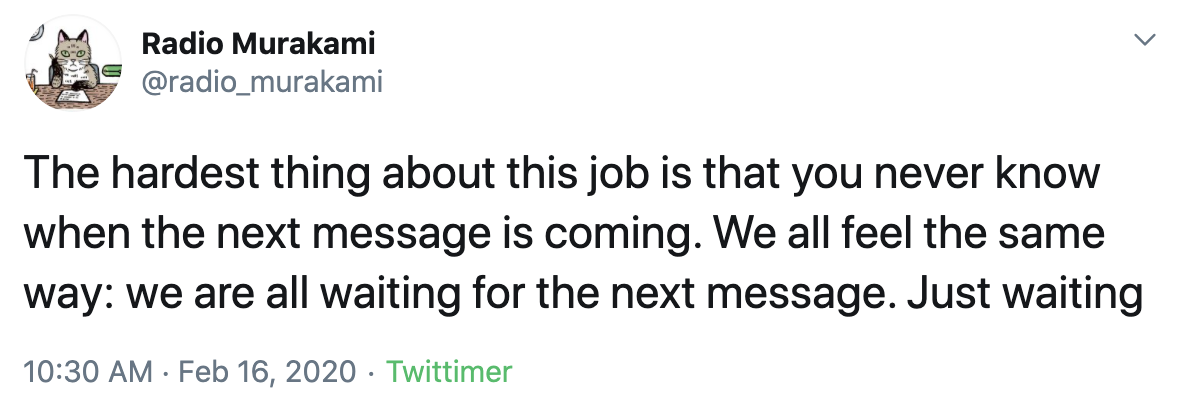
Currently tweets from the Radio Murakami bot are generated from the trained GPT-2 model. We use a seed text as manual input and the completed sentences are then semi-curated by us. Like Murakami, it tweets intriguing descriptions of everyday life and other musings.
Here are some of my favourites:


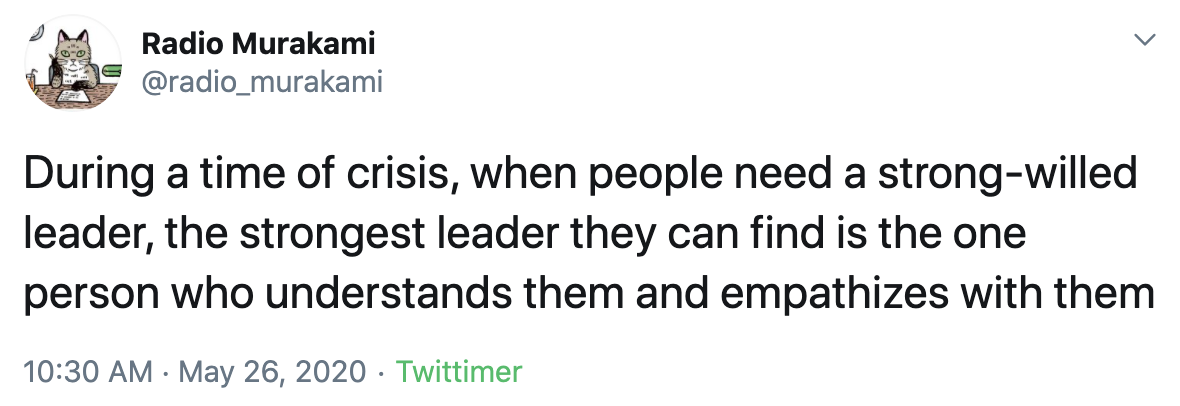
It is also capable of discussing current affairs sometimes, though in a subtle way:
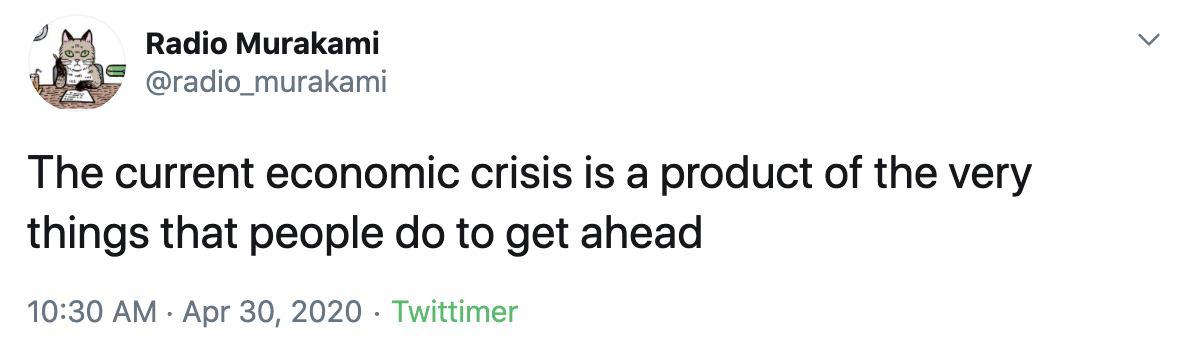
If you’d like some Murakami goodness delivered to you daily, you can follow the bot here 🤖!
Future work#
There are a few more things we’d like to look at —
- We can definitely do with more automation on choosing the best tweets. One way to do this is use another model such as BERT as a discriminator to refine the tweet generation model. We are currently experimenting with this
- We are tying our more inspirational quotes to designs, which means having to pull in images that are relevant to the quotes and size them accordingly. This would require some level of effort, but some automation here may be possible too!
- If you want to get involved in the project, or interested in designer quality prints from quotes by the bot, please register your interest here for more updates in the near future!
P.S. I was enjoying this playlist while writing this. Hope you’d enjoy it too 🎧
This piece was co-authored with Paul Tune. You can follow him on Twitter or checkout his personal website!
References#
[1] Radford A., Wu J., Child R., Luan D., Amodei D., and Sutskever I., “Language Models are Unsupervised Multitask Learners”, 2019. (link)
[2] Alammar J., “The Illustrated GPT-2 (Visualizing Transformer Language Models)”, 2019. (link)
[3] Anderson A., Maystre L., Mehrota R., Anderson I., Lalmas M., “Algorithmic Effects on the Diversity of Consumption on Spotify”, WWW ’20, April 20–24, 2020, Taipei, Taiwan, pp. 2155–2165. (link)
[4] Devlin J., Chang M. W., Lee K., Toutanova K., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, 2018. (link)